Our Testing
Doc-First Development
The tests for pometo are generated from the documents. Sopometo’s doc-first development process is a close relation to traditional test-first development.
Any features added to the system need to have associated documentation (and hence tests-generated-from-the-documentation) written as we go along.
Documentation is stored in a structured set of directories under docs/. To add a page to the table of contents please edit docs/_data/contents.yml. Please follow the basic dev cycle:
- create new docs in the
_work_in_progressdirectory - commit the docs with WIP in progress on the feature incrementally
- as long as the full test suite passes
- write your code until the tests (including your WIP tests) all pass
- raise a PR that includes:
- migrating the docs page to its final place
- adding an entry in the
contents.ymlto make sure the docs page appears in the published docs page
Feel free to raise a PR to review a new docs page in the WIP directory before starting coding it up.
Please manually check that the documentation builds before you commit your change. (There is one known and unavoidable problem: two left curly brackets side by side is interpreted as a template command and you need to write your apl a bit more spaced out - { {.
To build the docs locally start the docker file and cd /pometo/docs and run the bash script ./run_jekyll.sh. This will build the docs and serve them on 0.0.0.0:5000. They can be accessed on your host machine at http://localhost:5000.
(If you have problems with ./run_jekyll.sh telling you it can’t find gemfiles, etc, etc, consider deleting the Gemfile.lock file and forcing a docker rebuild with docker-compose build --no-cache.)
You should write your documentation top down - the easy basic and normal cases at the top, errors, edge cases, exceptions futher down.
The tests can be generated in two formats - Eunit tests and Common tests.
Eunit tests are great for simple isolated development - adding a new function for example. Common tests are better for work that touches the lexer/parser and runtime where. The Erlang Common Test framework builds a local website with a detailed history of everytime the test suite has been run.
The Eunit test suites are generated in reverse order - so the top example becomes the last test. This means when you make a change a whole lot of tests fail the bottom failure is the test case you should fix first.
How To Write Docs Pages As Tests
Docs pages have a simple format.
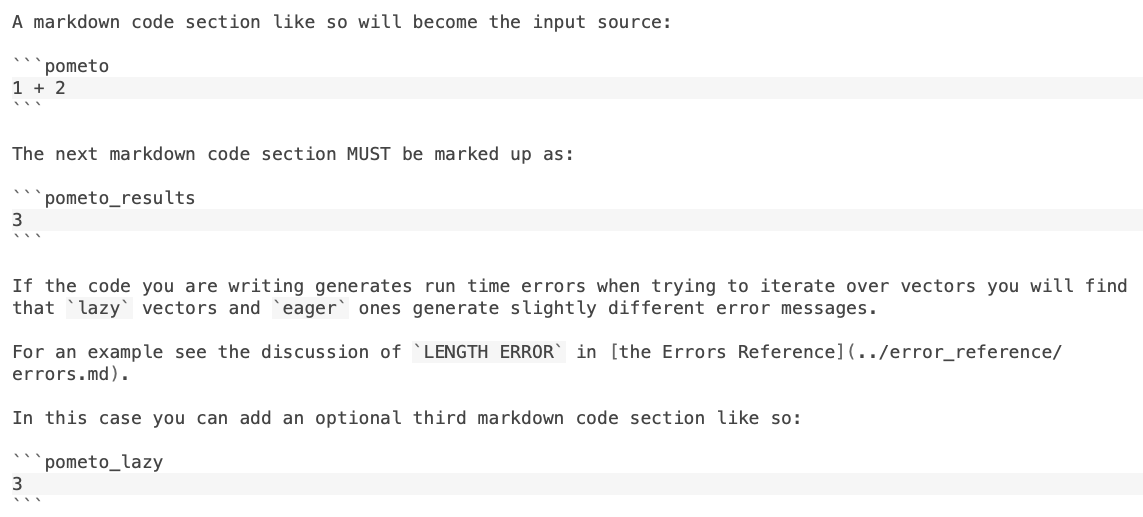
A markdown code section maked as a pometo code block so will become the input source:
1 + 2
The next markdown code section MUST be marked up as a pometo_results code block:
3
Handling Lazy Errors
If the code you are writing generates run time errors when trying to iterate over vectors you will find that lazy vectors and eager ones generate slightly different error messages.
For an example see the discussion of LENGTH ERROR in the Errors Reference.
IMPORTANT: if the output contains quoted strings they must be escaped in the documentation.
In this case you can add an optional third markdown code section marked as pometo_lazy code block:
3
The source code for this with the code block markings visible looks like:
(in this case the lazy and the eager evaluation is the same so the contents are the same).
This allows you to give two different results for a given Pometo code fragment.
NOTE:
- this is only offered for
runtimelazyerrors where they cannot be sensibly normalised and should be used rarely. This test suite was 345 tests in before one needed to be written
Handling Interpreter Print Trees
Some decisions about evaluation are handled differently in the interpreter than in the compiler. Typically something will be resolved line-by-line in the interpreters but left in an runtime data structure for the compiler to handle.
In this case you may get different results using pometo_stdlib:print_trees and can use a code block marked pometo_interpreted to add different results. (see the smoke tests for an example).
NOTE
This is rarely required - and never for tests that return actual results to the users - only for debugging tools that peek into the data structures.
The pometo_docs_to_tests rebar3 plugin will turn this page into an Eunit test file our_testing_tests.erl in test/generated_tests and it will contain the six variants on a single test, for example: how_to_write_docs_pages_as_tests_1_compiler_force_unindex_test_/0.
The pometo_docs_to_ct_tests rebar3 plugin will turn this page into an Common test file our_testing_SUITE.erl in test/generated_common_tests and it will contain the six variants on a single test, for example: how_to_write_docs_pages_as_tests_1_interpreter/0.
It names each test from the second level heading that preceeded it in this case from ##How To Write Docs Pages As Tests with an incrementing sequence number.
The sequence deliberately increases over the whole document page - this is to ensure there isn’t a test name clash if the same sub-heading is used.
You can then run the Eunit tests from this page with rebar3 eunit --module=our_testing.
To run the common tests from this page use rebar3 ct --suite=test/generated_common_tests/our_testing_SUITE
(The entire suites can be run with rebar3 eunit and rebar3 ct)
This is what the generated test looks like. The pometo section has been mapped to the code variable. The pometo_results section has become the expectation.
Note that six tests have been generated - an interpreted, a compiled, a lazy compiled, an indexed compiled, a force index and a force unindex one. (The interpreted code path is run in Rappel - the pometo REPL.
Essentially data coming in from Erlang/Elixir will tend to be linked lists and these are represented in Pometo as lazy vectors - vectors that don’t know their size. On the first pass through a traverse they are automatically converted to eager vectors - ones that do know their size.
For index operations the internal representation of a vector must be indexed - and again the conversion is handled automatically. The lazy and indexing test suits just ensure that the code paths can handle that.
eunit macros don’t play that well with unicode and failures tend to be hard to decipher. To that end a commented out debugFmt statement is generated. Uncomment that, re run the tests and voila readable failure reports.
NOTES:
- sometimes you want to write examples that you don’t want to turn into tests, this might be because of duplication or some other reason. You can subsitute
aplandapl_resultsforpometoandpometo_resultsin your text. The code formatter has (will have) the same styles for these - don’t write blank code block if you are just quoting some bollocks. Give the code block a type of
bollocks- this makes thegreptrick usable - a little discipline goes a long way here
Go on, try writing doc tests.
What Happens If A Million Tests Fail?
Don’t panic. Tests suites shadow each other. That is to say if a particular test fails we can predict which other test suites will also fail. Understanding the shadow order helps you decide which of your million failing tests to fix.
The core lexer/parser tests are not generated from docs - run them first.
To do that simply delete all the generated tests (they are not stored in git the documentation is the primary source of them) rm test/generated_tests/*.
Run rebar3 eunit and if there are any failing tests in there fix them. If there is a primitive lexer or parser bug you would expect all tests that use the failing feature to fail also - and therefore this test failure will cast its shadow onto the feature test suites.
Once the primitive tests are all passing make sure the runtime smoke tests passes. This is described in smoke tests
To do this first generate the documentation with rebar3 pometo_docs_to_tests and then run rebar3 eunit --module=smoke_tests_tests
(the test generator appends _tests to the documentation page name which is why Smoke Tests becomes smoke_tests_tests.)
This test suite just tests the execution paths of pometo_runtime and again a failure here will shadow onto lots of feature tests. Once this test paths you are left with your final feature bugs to fix.
Rebar Has Crashed!
Ah, are you sure you types rebar3 .... and not rebar ... becuz rebar is also installed as a tool and it doesn’t play with pometo because of our custom rebar3 plugin.
Working On The Runtime
If you are working on the runtime please to add the simplest smoke tests to the documentation page smoke tests